
OpenTelemetry is an open-source standard for the observability of distributed systems and microservice-based architectures. It provides a set of APIs and SDKs to collect telemetry data from those running systems and applications. This framework standardizes the way logs, metrics and traces are collected, correlated and shipped to observability or analyzing tools. This library is vendor agnostic and does not lock you into specific tooling for monitoring purposes.

Why OpenTelemetry?
The OpenTelemetry standard decouples telemetry data collection from your applications and the monitoring tools. These days, most proprietary monitoring tools provide their way of collecting data from your apps and sending them to be monitored. A significant downside of this approach is that you will get locked to that specific vendor in terms of configuration and roadmap of features it provides. The OpenTelemetry standard offers a way to instrument your apps, even in a polyglot environment, in a vendor-neutral manner. You can switch your monitoring tools quickly as long as your incoming tool supports OpenTelemetry data formats.
Instrumentation in a polyglot environment at an enterprise level is easy with the OpenTelemetry standard. It provides agents that automatically work with your app, prepare telemetry data, and send it to the monitoring tool. Suppose you have platforms like MuleSoft that do not yet have ready-to-use agents from OpenTelemetry. In that case, the project provides APIs and SDKs to manually instrument your MuleSoft application to collect and generate OpenTelemetry data. This is discussed in other sections in more detail.
Several vendors like Splunk Observability, AppDynamics, New Relic, Google Cloud, Lightstep, Elastic, etc. have already started supporting OpenTelemetry based data to flow into their systems for observability. Therefore, if you are already using a tool for monitoring, there is a good chance that it supports OpenTelemetry based data inputs or at least would be supported soon.
OpenTelemetry Architecture
Let’s try to understand some basic building blocks of OpenTelemetry.
Span (or event): A span is a single unit of work that happened in your application. For example, an HTTP request is received, or a message has been published to a queue. Each span encapsulates different types of information such as the name of the operation, start and end timestamps, links to other spans, etc.
Trace: A trace represents a series of linked spans/events. For example, a single business transaction that flows through multiple applications in your microservices environment. A transaction will create a trace when initiated. A trace will register each event with a span in the transaction. That’s so that we can view the whole trace in the observability tool.
Metrics: A metric is a numeric measurement of a specific facet of a running application, such as CPU utilization or successful HTTP requests per second. OpenTelemetry maintains an internal registry of metrics and regularly exports them with the proper MetricsReader. A few libraries automatically register metrics based on JMX values, but since Mule 4 doesn’t register metrics with the JMX, we can’t use these libraries.
Instrumentation: Instrumentation is the process of preparing your applications to generate OpenTelemetry based data for monitoring. If your distributed system environment consists of applications written in widely popular languages (Java, Python, Go, Ruby, etc.), the OpenTelemetry project provides ready-to-use binaries. These binaries, known as agents, go along with your applications and generate the telemetry data in a standardized manner. These binaries could either go along per application or in a runtime environment where multiple apps could be running.
All these spans and traces will be created adhering to the OpenTelemetry standards using one of the below two ways.
- Automatic Instrumentation: This is the easiest way of instrumenting your application to produce spans and traces. OpenTelemetry project provides programming language-specific agents to go with your apps or in a runtime environment that takes care of creating these spans and traces.
- Manual Instrumentation: If you have an application written in a domain-specific language like MuleSoft, you need to manually instrument your application to generate telemetry data consisting of spans and traces. This requires some development effort to extract or detect events in your app and generate spans and traces. OpenTelemetry provides APIs for this development. This is further discussed in detail in the following sections.
Instrumented Library: A library that has been instrumented either automatically or manually and is ready to generate spans and traces.
After creating your spans and traces, you need to send your telemetry data to one of the analyzing tools. We can do that using an exporter, which we can configure along with the instrumented library.
Exporter: An exporter extracts telemetry data from your app to an analyzing tool. Exporters are a part of what OpenTelemetry provides with its APIs and SDKs. You can configure an exporter to your instrumented library by specifying the necessary environment variables that point to your observability platform.
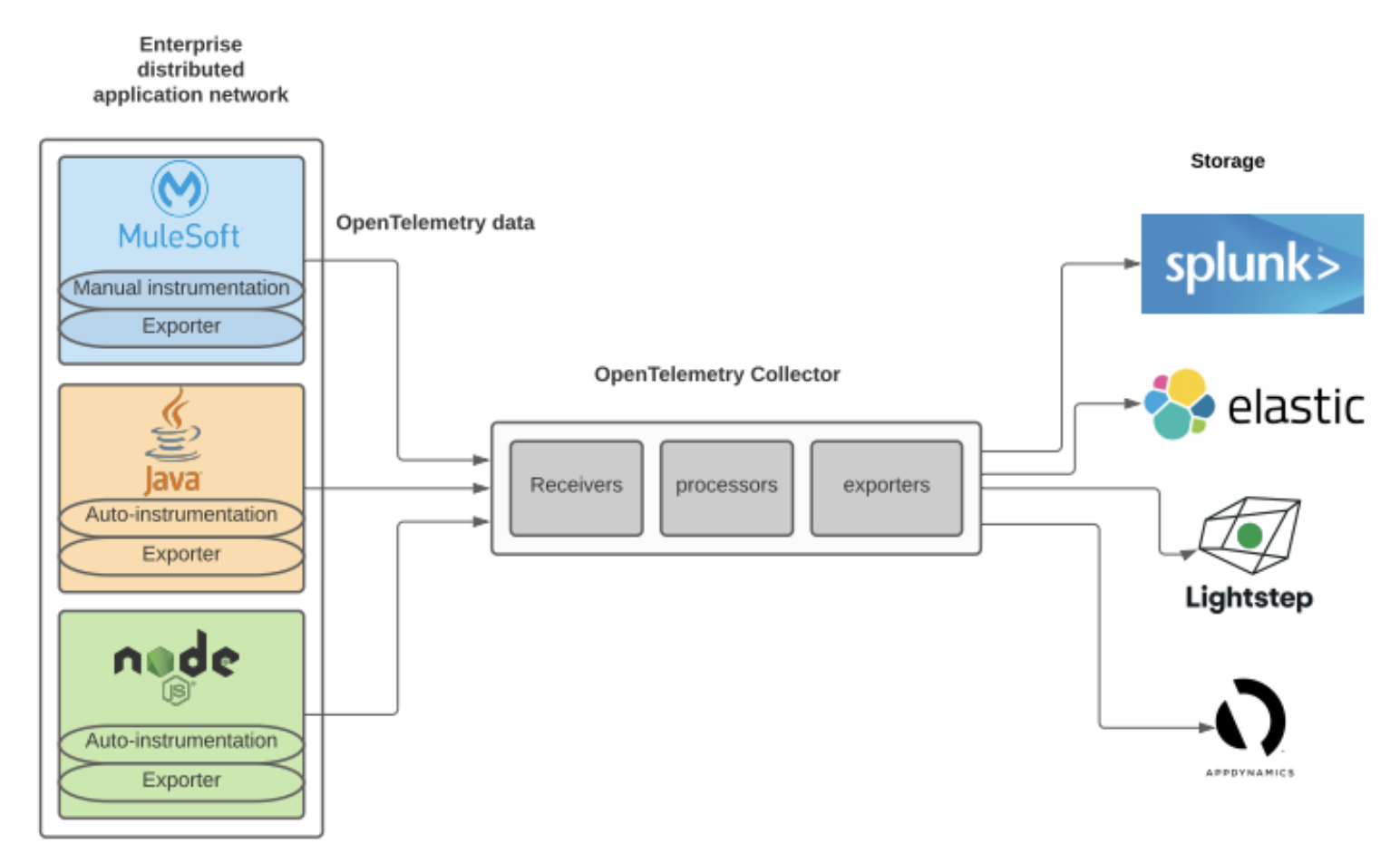
Collector: This is a single library provided by the OpenTelemetry project, which is used to receive, process, and export telemetry data to analyzing tools if needed. This can be used as a separate standalone agent running alongside your apps in your distributed environment or a separate gateway/proxy.
You may export telemetry data right from your service by configuring exporters or via collectors. Some organizations may prefer abstracting the export process out of the application’s code. In this case, you can use a collector which receives telemetry data from one or more applications and exports it to the analyzing tool. As this collector can be deployed as a standalone service or proxy, you can configure your applications to export data to the collector. Exporting data to the collector performs additional responsibilities, like enhancing telemetry data with additional metadata, batching, retry, encryption and other tasks that client instrumentation code would need to handle. We recommend using the collector both as a sidecar agent or as a gateway. You may run a collector as a gateway in your organization’s DMZ if your distributed environment applications cannot communicate with external systems on the internet or have security constraints that block all the outgoing traffic from your apps.
Monitoring With Tracing vs Logs
Logging
Application logs are crucial troubleshoot applications as it helps you view the flow of the program and the stack traces for exceptions. A good set of logs combined with exception stack traces should give you all the necessary details to troubleshoot and understand what exactly went wrong with the app in the event of an error.
However, a simple unstructured log or the exception stack trace alone would not help much if you have a distributed system with many microservices deployed in various cloud providers. Logging should be consistent and structured format and often be used in conjunction with a logging framework such as Apache Log4j2. The logging framework provides all the flexibility of handling the log statements generated by your application to perform additional tasks like enriching with additional metadata, formatting, sending them to various remote locations for storing, etc. Structured logging is crucial for the organization to parse the logs in a unified manner. Structuring your logging helps significantly in building alerts or dashboards in a log analyzer tool. If you are in the MuleSoft world and want to generate structured logs, use this custom logger: avioconsulting/mule-custom-logger
Tracing
Tracing is mainly used to monitor the performance of your distributed system. Distributed systems need tracing to identify how an event ended up at a particular point and how long it took, which helps find the slow event and identify bottlenecks in your entire application network.
A standard tracing framework like OpenTelemetry is beneficial to instrumenting your applications to produce spans, traces and metrics, as well as a standardized way to ship traces to a monitoring tool.
Ultimately, tracing helps you pinpoint where the problem is in your entire application network and logging enables you to gather more details about that problem. Therefore, both tracing and logging are helpful for distributed systems. An ideal target setup for this would be to send both application logs and the traces to one monitoring tool to visualize them in a unified manner and jump to log events of a span or trace and vice-versa.
OpenTelemetry With MuleSoft Applications
The goal here is to generate OpenTelemetry data for MuleSoft applications running in either CloudHub or On-Premise. As there is no ready-to-use agent for MuleSoft applications to generate telemetry data, we need to develop our agent that listens to the MuleSoft notifications to generate spans and traces using OpenTelemetry APIs.
MuleSoft provides some interfaces that we can implement to listen to the events from the running Mule app. For example, We can implement PipelineMessageNotificationListener to listen to the flow start and end events used to start and end a trace. Additionally, we can implement MessageProcessorNotificationListener to listen for Mule processor start and end notifications and use OpenTelemetry APIs to create and link spans.
Below is a sample code to capture/listen to Mule flow start and end events which eventually create or end OpenTelemetry traces.
public class MuleFlowNotificationListener
implements PipelineMessageNotificationListener<PipelineMessageNotification> {
private Logger logger = LoggerFactory.getLogger(MuleFlowNotificationListener.class);
@SuppressWarnings("deprecation")
@Override
public void onNotification(PipelineMessageNotification notification) {
logger.debug("===> Received " + notification.getClass().getName() + ":" + notification.getActionName());
switch (notification.getAction().getActionId()) {
case PipelineMessageNotification.PROCESS_START:
OpenTelemetryMuleEventProcessor.handleFlowStartEvent(notification);
break;
case PipelineMessageNotification.PROCESS_END:
break;
case PipelineMessageNotification.PROCESS_COMPLETE:
OpenTelemetryMuleEventProcessor.handleFlowEndEvent(notification);
break;
}
}
}Below is an example of handling the Mule message processor start event to create or link a span and call on the Mule message processor end event to end the span.
public class OpenTelemetryMuleEventProcessor {
// ........
public static void handleProcessorStartEvent(MessageProcessorNotification notification) {
logger.debug("Handling start event");
Span span = null;
try {
SpanBuilder spanBuilder = OpenTelemetryStarter.getTracer().spanBuilder(getSpanName(notification)).setNoParent();
span = spanBuilder.startSpan();
} catch (Exception e) {
System.out.println(e);
}
transactionStore.addSpan(getTransactionId(notification), getSpanId(notification), span);
}
// ........
public static void handleProcessorEndEvent(MessageProcessorNotification notification) {
Span span = transactionStore.retrieveSpan(getTransactionId(notification), getSpanId(notification));
span.end();
}
// ........
}
Combined with MuleSoft notification listeners implementation and OpenTelemetry APIs, we can successfully build OpenTelemetry based spans and traces that could then be shipped to an external analyzing tool to monitor telemetry data.
OpenTelemetry agent for MuleSoft is currently under works in AVIO Consulting and would be open-sourced in GitHub as soon as it is production-ready to use with both CloudHub and On-premise environments. We’re basing our code on the OpenTelemetry SDK Autoconfigure library. This allows us to configure the exporters using only environment and system variables rather than manually implementing code to handle each scenario.
Limitations
There are currently a few limitations around the metrics library that prevent us from including it in our Mulesoft OpenTelemetry Agent. The Java API for metrics hasn’t been fully agreed upon by the Cloud Foundation, so it hasn’t been fully hooked up in the OpenTelemetry SDK Autoconfigure library. The workaround is to instantiate a MetricsExporter (such as the LoggingMetricExporter) and provision an IntervalMetricReader to export the metrics on a schedule.
View Telemetry Data
The end goal of observability is, of course, observing your application. This requires exporting your traces and metrics to a visualization tool such as Grafana or Splunk. Thanks to OpenTelemetry’s vendor-agnostic approach, you can choose any visualization tool that supports the OpenTelemetry format. We used a Grafana instance fed by Loki to visualize our sample MuleSoft application.

The above screenshot shows an example of a trace. You can see that the topmost bar (the flow) spans across the whole trace while the shorter-lived processors (loggers, transform) are staggered below. When you have a flow reference to another flow, this entire process would be tiered below the existing long-running flow span.
{{cta(’52f6509f-16e3-4145-b847-f28b0cc144d3′,’justifycenter’)}}
