XPath and XSL can be intimidating, but in this blog I will attempt to demystify some aspects whether you are new to the technologies or are experienced. I will explain useful basic and advanced features that you may not have known about or have not dared to use.
What are XML, XSL, and XPath?
To explain XML to people new to these topics, I like to equate it to something you may be familiar with, such as a database and SQL. XML is to data in a database as XPath is to SQL. This table contains this and other useful analogies between these two technologies.
| XML to Database Analogies | |
| XML | Database |
| XSD (XML Schema) | Database schema |
| XML | Database data |
| XPath | SQL select |
| XSL | PL/SQL |
XML

XML is a representation of data with simple notations to use. The notations consist of elements and attributes. Elements start with a notation such as <invoice> and close with the notation </invoice>. Elements can contain attributes, such as <invoice pk=”23”> or other elements or data as shown here.
| Element containing other elements | Elements containing data |
|
<invoice pk=”23”> <invoiceNumber>4</invoiceNumber> </invoice> |
<invoiceNumber>4</invoiceNumber> |
Elements without content can also open and close on the same line, for example,
<invoice/>
The sample XML document below that will be used throughout this blog is based on a simple invoice schema. As you can see, the XML has a list of invoices and each invoice has a list of line items. The invoices are generated against purchase orders, such that many invoices can be associated with a single purchase order. Note also the namespace attribute xmlns. More on that later.
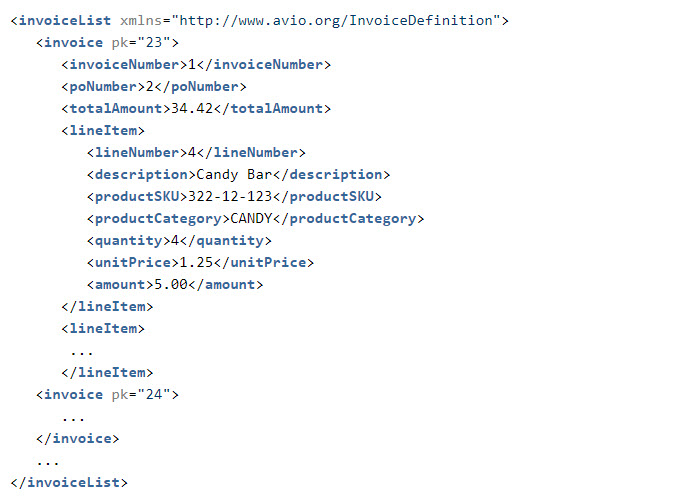
Here is another look at the data, without the invoice line items. This data has three invoices associated with PO = 2 and two with PO = 4.

XPath
Using our analogy, XPath is like a SQL-select statement. It is used to select information from data—our invoice XML document in this case.
For BPEL developers, it is useful to know that XPath is used in all assignments. For BPEL developers and everyone else, you should know that it is used in most all XSL statements. So if you want to work with XSL, you will need to understand how XPath works.
XPath navigates down to elements in an XML document similar to the way you change directories in MS-DOS or a Linux shell. You can change directories on your computer and see other directories or files in these directories. Likewise, XML elements can be navigated to find other elements or data in them. So elements are like directories and files are like data in the elements. One exception to this analogy is that elements can also contain attributes. For now, think of attributes like metadata for the element.
For example, the following XPath statement navigates down the invoice document from the root level element, invoiceList, to the invoice elements.
/invoiceList/invoice
This XPath statement will return a list of <invoice> elements, or a node set. The preceding “/” of an XPath statement, as in our directory comparison, refers to the root element. Here <invoiceList> is the root element of our sample document. Since our sample document contains a list of <invoice> elements, this XPath statement returns a set of elements, or a node set.
Just like with your computer, if you don’t precede the path with slash (“/”), a relative path is assumed. When we get into XSL a bit more, you will see how the current path can change from the root element. For now it’s sufficient to know that you can navigate down from a current location or from the root node. Just like in MS-DOS or Linux shells, the “.”, “./” and “../” notation refers to the current node or element, a sub-node, or parent node. Here are some other useful things you can do with XPath.
| XPath1
|
Returns | Notes |
| /ns0:invoiceList/ns0:invoice | a node or node set of invoice | The first “/” indicates we must start at the root node |
| /ns0:invoice | null | Since we have a leading “/”, and the root node is not invoice, this returns nothing |
| /ns0:invoiceList/ns0:invoice[2] | returns the second element in the array of invoice elements | XPath uses “1”-based indexing. so [1] is the first element in an array |
| ../ns0:poNumber | PO number | Navigates up one level when after various select statements, and the for-each statement. |
| ns0:invoice/@pk | the value of an attribute, 2 | Return values of attributes2, If we had an element like, <ns0:invoice pk=”2″ …> |
| /ns0:invoiceList//ns0:lineItem
|
a node or node set of lineItem | The “//” is like a wild-card search. It navigates down the xml tree looking for any node that matches the element name. In our example, it skips over the invoice and finds the lineItem nodes underneath it. |
Notes:
1 We use namespaces prefixes, ns0:invoiceList/ns0:invoice, where. “ns0:” is the prefix. There will be more on that later
2 Attributes, like pk in this example <invoice pk=”2” …> can be addressed using the “@” symbol.
XPath Results and Filters
XPath statements returns a result of different types of data, such as strings, integers, decimals, a node, or node sets. The XPath interpreter will return its best guess as to what it thinks you are looking for. In our case, if the expression is /ns0:invoiceList/ns0:invoice, it’ll return a node set. The expression
/ns0:invoiceList/ns0:invoice/ns0:poNumber
will return an integer (if possible) or a string.
There are conversion functions, like string(xpath) and integer(xpath) that can force the result into a certain type, but they aren’t usually needed. If the data can fit into a string or integer, it will return that type; otherwise, it will return a node or node set.
When XPath returns a node or node set, the result can be placed into a variable and operated on again with other XPath statements. To specify the set of nodes you need, you can use filters. You’ve already seen one type of filter, the index of an element. Indexes, like filters, use square brackets with an integer, like [2]. However the square brackets (“[ ]”) can also contain expressions for filter node sets. These expressions can be very complex and you should think of them as a where clause for an SQL-select statement. For example,
/ns0:invoiceList/ns0:invoice[ns0:poNumber=’2′]
Here the expression in the filter ns0_poNumber=’2’ is evaluated for each node in the <invoice> array. If true, it adds the node to the node set. Relative addressing is used within the filter with no proceeding “/”. The filter [/ns0:poNumber] would be incorrect. Likewise, do not separate the filter with a “/”.
/ns0:invoiceBatch/ns0:invoiceData/ns0:invoice/[ns0:poNumber=’2′] would be incorrect.
Namespaces: What’s in a name?
What’s in a name? When working namespaces and XSL, a lot really. The computer will not know how to parse the document if you’re not careful, so let’s break it down.
Take for example an element name such as <table>. In one XML document, the table element may be referring to something that has three or four legs and a surface. But in another it can be something that is supposed to have columns and rows within it. With XML, you can combine several different sets of data into a single document. So if you use XPath, for example, in a document where both types of table elements are used, which one will you get? That’s where namespaces come in.
Namespaces are used to classify elements and attributes in an XML document and are defined in a namespace attribute in the document. The namespace attribute always starts with xmlns, short for xml namespace. It can also specify a prefix like xmlns:tns. It is usually provided in the root element of the document, like this:
<invoiceList http://www.avio.org/InvoiceDefinition”>http://www.avio.org/InvoiceDefinition“>
<invoice>
…
</invoiceList>
This creates a default and more dangerous way to identify the element namespace for <invoiceList>. It is a bit more dangerous since it is also providing the namespace for everything in it. In the above example, the <invoice> element and everything after would have this namespace.
Using prefixes is a better and more explicit way to use namespaces. Here the prefix, ns0, explicitly labels all elements in the document relating to the namespace as shown.
<ns0:invoiceList xmlns_ns0=”http://www.avio.org/InvoiceDefinition“>
<ns0:invoice>
…
</ns0:invoiceList>
The namespace is a string and can be anything you want it to be. It usually is in the form of a URL. The URL, if it resolves, may return a governing document, such as the XML schema or XSD for the XML data. Remember our analogy: XSD is like a database schema. It defines the structure and related namespace, for the content of the XML.
XSL – The Programming Language for XML

Using our analogy, XPath is to a select statement as XSL is to PL/SQL. Now that you have been exposed to XPath, we will use it to construct a new XML document using XSL. An input XML document will be operated on by an XSL Transformer and XSL document as shown to create a new output XML document. Most IDEs have built in XSL transformation engines, and links are provided in the reference section below on how to use them.
Typically only one input XML document can be used by the transformer. However, if more than one input document is needed, the subsequent documents are treated as parameters or variables. You will declare as many other inputs as parameters
<xsl:param name=”docTwo” />
and extract data from them using a dollar sign, as you would data in variables, as shown here:
<xsl:value-of select=”$docTwo/xpath/todata” />
We will discuss more about how to use the xsl:value-of and variables below.
Like any language, however, XSL has its own set of statements, such as for-each, if, choose, and value-of. However that’s as far as this analogy goes. The structure of XSL doesn’t follow the same structure as other programming languages. Its structure matches the structure of the desired output.
So if you want an output like this, with key structural elements in yellow,
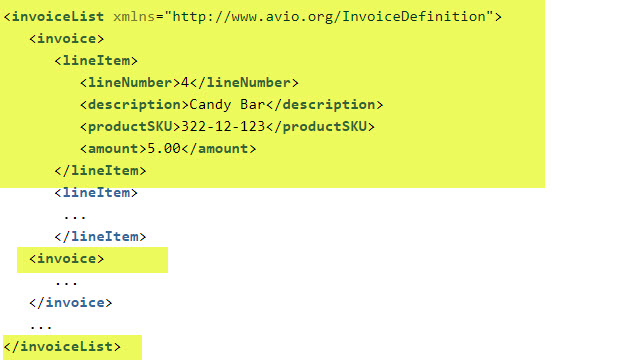
the XSL Document will have the same form, matching the key elements again shown yellow.

The yellow is highlighting the desired output using namespace prefixes of the output document. To pull data from the input document, we use XSL statements such as xsl:template, xsl:for-each, and xsl:value-of.
Notice the namespace prefixes; xsl and ns0. Here, not only do we have an XML document with two namespaces, the two namespaces are thrown in together. This is necessary since the XSL transformer will use this document, which by the way is a valid XML document, to pull data from the input document and structure the output in the desired form. Because of these namespace prefixes, the transformer engine can tell what is an instruction to be interpreted (for example, <xsl:for-each>) and what is just sent to the output (<ns0:invoiceList>).
A common attribute for many XSL statements is the select attribute.
<xsl:value-of select = “ns0:amount” />
Select attributes contain XPath statements. Recall that XPath can return many different types of objects: integers, string, nodes, and node sets.
Note: XSL can be used to generate a text document output, not just XML. We will only use is to output XML.
Variables
Variables can be defined almost anywhere in an XSL document. If you place the definition before the initial template statement <xsl:template select=”/” … >, it acts like a global variable. If you use it right after a statement, for example <xsl:for-each>, it creates a useful local reference to a value for operating on data specified in the for-each loop.
For example, let’s create a variable to contain the maximum PO number in the input document. Since it is global, it will be placed before the <xsl:template> statement. We use the aggregation function max and wild-card “//” to extract the largest PO number in the document like this:
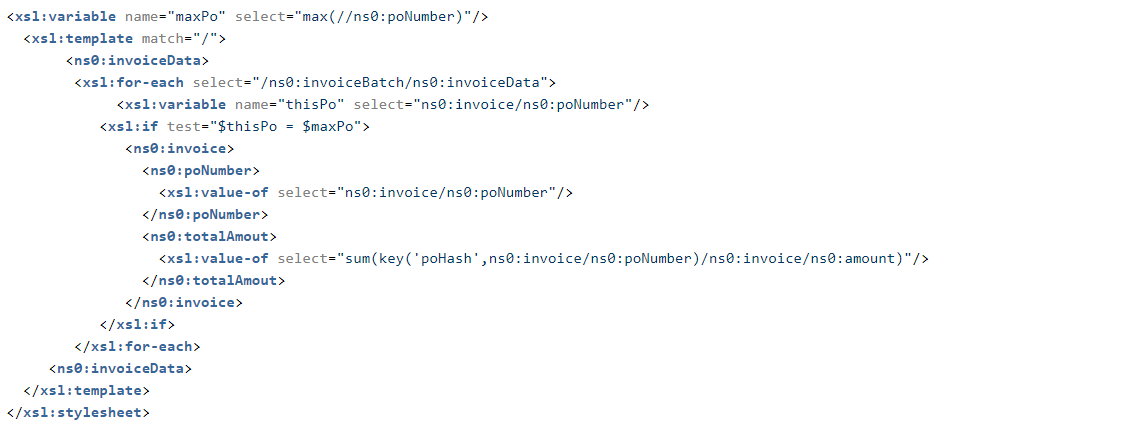
In this example, note the placement of the variable maxPO. Note also that we have a local variable, thisPo. This is placed within the for-each loop, where relative addressing will set this variable to the PO number the loop is working on.
<xsl:variable name=”thisPo” select “ns0:poNumber”/>
The use case may not make much sense, but it illustrates how to create and use variables with different scopes. Let’s say we need to do something special as we loop through invoice elements for the poNumber that is the largest in the input document.
When we loop through the list of invoices, we reference the variables using dollar (“$”) sign symbol. We can, for example, compare the current PO number with the max value in a xsl:if statement. Again, it may not make sense why we are checking for the max PO value, but it does show how to create variables and use them.
<xsl:if test=”$thisPo = $maxPo”>
Advanced Transformations: Pivoting, Aggregations, and Hash Maps
In some scenarios the output data needs to pivot across data in the input. For example, our invoice XML has a parent-child relationship between an invoice and the PO number. Several invoices may be related to a single PO. Let’s say we need to add up (aggregate) all the invoice totals for a given purchase order and output the result. Since there are several invoices for a given poNumber, we will need to pivot on poNumber. The resulting XML should have a unique record for each PO with the total of all invoices for the PO.
In order to do this, we need to use three new features of an XSL document: the hash map, node set functions, and aggregation functions.
xsl:key – Hash Map
To create a hash map, we will use the XSL statement xsl:key. We will create the hashmap called poHash to contain a node set of ns0:invoice elements by PO number. This statement defines the hash map we need.
<xsl:key name=”poHash” match=”/ns0:invoiceList/ns0:invoice” use=”ns0:poNumber”/>
In an XSL document, you can have as many hash maps as you want. To tell them apart, we name them, for example poHash. It consists of a map of node set according to the match statement. The hash map uses as its key ns0:poNumber. Note that relative addressing is used between the match XPath statement and use statement, which can also be XPath and XPath filters.
To get a list of invoices for a given PO number, say four, we can use the function key(), in an XSL statement like:
<xsl:copy-of select=”key(‘poHash’,’4′)”/>
This will return the following node set from the input document where there are two nodes in this particular PO number.
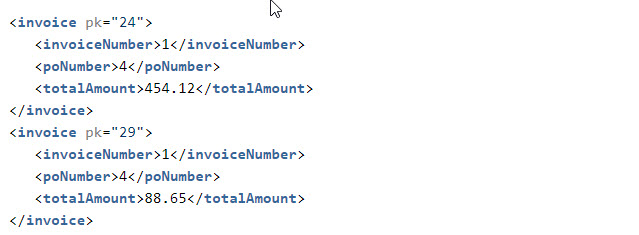
If you look at the original data you’ll see that there are two unique PO numbers in the data. To output one record for each unique PO number, we need to pivot on the PO number and then aggregate on the amounts. To do this, we will simply skip over the records where PO number has already been outputted. That will give us the number of records we need, one for each PO number. We then aggregate the invoice amounts when it is outputted.
In Java, you could use the keySet() method to get a set of unique PO numbers. We don’t have that in XSL, but we can trigger the output whenever we find the first <invoice> element for a given PO number. To do this, we introduce the generate-id() function. This function uniquely identifies elements in the input document with elements in the hash-map node sets. If the element ID of the input is the same as the element ID of the first element, grouped by PO number in the hash map, we have found the first element for a given PO number. We will skip the other elements in the set.
The generate-id function is similar to the object hash-code in Java. In XSL when the input document is parsed, a unique ID is given to each node. That identifier stays with the element even if it is associated with variables, hashmaps, or parameters.
We can use the generated ID in the loop through the list of XML invoice nodes from the input. We will test the ID of each node against the first node for the PO number in the hash map. When the ID of the <invoice> element is the same as the first node in the hash map, we will output it. If not, we will skip it.
Pivoting on PO Number
In XSL we use xsl:for-each to loop through an array of elements.
<xsl:for-each select=”/ns0:invoiceList/ns0:invoice”>
As we loop through elements with the for-each statement, the current reference changes to each <invoice> element in the array. Relative addressing can be used within the loop such that
generate-id(.)
will return the hash code for that current <invoice> elements. And the statement
generate-id(key(‘poHash’,ns0:poNumber)[1])
returns the hash code of the first <invoice> element in the hashmap. Note here again, the PO ns0:poNumber is relative to the current <invoice> element in the for-each loop.
Putting the two statements together, we can test to see if we have the first element for the given PO number in this xsl:if statement.
<xsl:if test=”generate-id(.) = generate-id(key(‘poHash’,ns0:invoice/ns0:poNumber)[1])”
Since the reference changes within the for-each loop, we can also get data for each node using relative addressing and a xsl:value-of statements, for example,
<xsl:value-of select=”ns0:poNumber”/>
Aggregations
To get the sum of all invoices for a given PO, we use the aggregation function sum():
sum(key(‘poHash’,ns0:invoice/ns0:poNumber)/ns0:invoice/ns0:amount)
Note here, that the function key(‘poHash’,…) returns a node set. We can then build off of this with an XPath statement to get the amount: key(…)/ns0:invoice/ns0:amount. Since there may be several nodes in the node set, sum() will add them up.
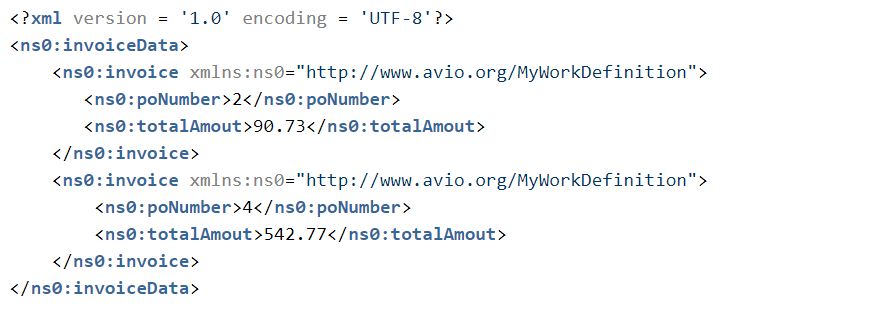
Putting this all together, you have the following XSL.

This produces the following output.
Where to Go From Here
The methods described in this blog are pretty much all you’ll need to work with XSL. If you need to get more out of XPath or XSL than what is described here, you’re probably in situations where the output is significantly different from the input. These situations require more profound transformations, and you should probably look into breaking down the transformations into parts with xsl:call-templates, xsl:apply-templates and xsl:template statements. These statements will probably fill in what you need that was not explained here.
If you want to test the code and samples provided in this blog, the references at the bottom contain links that will help. IDEs such as eclipse, JDeveloper, or Intellij allow you to generate test data, add break points (JDev 12.2.1+), and debug your code. Even with these tools, however, fixing bugs can be difficult. But since testing an XSL is quick, you can try something, test it, change it, and try it again. This method is an effective way to narrow down and fix problems in an XSL.
References
Help with intelliJ – https://www.jetbrains.com/help/idea/run-debug-configuration-xslt.html
Help with eclipse – https://help.eclipse.org/neon/index.jsp?topic=%2Forg.eclipse.wst.xsl.do…
Help with JDEV – https://docs.oracle.com/middleware/1221/soasuite/develop/GUID-83DAC40D-…