
I assume the reader is actively creating MuleSoft applications using Anypoint Studio.
Control What You Can
As a software developer, nay, a reasonably sentient human, I constantly re-access what “works” for me. And by “works”, I am referring to what allows me to be effective and efficient. For this discussion, effective and efficient are tightly coupled, and for simplicity, I am going to assume the rest of the world is like me (dangerous indeed).
Regardless of one’s targeted goal, to some degree we are constrained by external factors. When developing software, we are often working within the constructs not set by us, and this can affect the accuracy of effort estimation. For example, access to legitimate test data during development can slow or more accurately extend the development process. Knowing datatypes will only get you so far, as most test failures occur when using/integrating with real or near-real data.
Additionally, projects are often managed in a way most comfortable to the client, understandably more aligned with the style of the project manager. It’s not uncommon within a large enterprise, to be shared on multiple projects, where a single “cage-free” project can time-slice your day out from under you. As practical technicians, we can (and should) raise these as concerns, but the inertia that exists within an organization is often difficult and futile to bend to your own personal aptitude.
At this point you might be saying, “hey man, where are you going with this?”.
Here’s my point. Setting the concept of extreme ownership aside (worthy of its own discussion as it pertains to software development), as developers, our efforts are best focused on what we can control. To this end, let us take a look at using Anypoint Studio efficiently, with less context switching, a clearer view of processing, and uniform view of the “code”. This can be achieved by spending the majority of development time in the Configuration XML tab (XML).
Development
Let’s assume that your RAML is completed and vetted for accuracy, as well as meeting the consumer’s needs. Let’s also assume that you’ve flushed out your backend dependencies (system APIs, 3rd party proxies, etc.) and that these are published in Exchange (connectors available for import). You’ve generated the stubbed endpoints and are ready to begin implementation of a given resource operation (HTTP verb/resource). Starting graphically, we add the appropriate components to the design palate in order to implement the integration pattern, transformation(s) and logic specific to our use case. So far I imagine most of us are on the same page. Now let’s take a look at the strengths of using the Message Flow view (graphical) and the Configuration XML view (XML) and when choosing one may be better than the other.
Message Flow View
Pros:
- Ability to visually and logically structure the message flow.
- Dragging connectors, scopes and components adds the required namespace definitions to the file.
- All processing flow is self evident – generally speaking.
- The Mule Properties pane has contextual information on component settings – handy when using unfamiliar components or connectors. As an aside, at the risk of insulting you, the reader, reviewing the MuleSoft documentation for any component that you are unfamiliar with is assumed.
- The only way to apply breakpoints for debugging.
- Generating MUnit scaffolding is made easier by selecting a flow followed by a couple of mouse clicks.
Cons:
- Connector properties are a level removed from the component icon in the graphical view – one needs to reference the Mule Properties tab for details. And while this is automatic within Anypoint Studio, it is still diverting attention from the flow – a micro context switch, if you will.
- Even simple flows can become visually “busy” with a try scope & error handling on specific types. It is not uncommon to handle specific lower level API or 3rd party proxied APIs to inspect the error response. (e.g. grabbing data for custom logging, Cloudhub Notifications, business level reprocessing, etc.) These on-error Types can be lengthy and not fully evident in the Graphical view.
Configuration XML View
Pros:
- Full view of component configuration – no need to “click” a component and then reference the Mule Properties tab.
- Search, and errors notices all resolve to line numbers within the XML – you’re already there.
- Component namespace definitions are automatically added when a component is manually added to a file. (Caveat: dependency must be in POM)
- Autocomplete is available (Mac: ctrl-sp) with all the available attributes to set for a given component.
- XML looks like code – can be formatted with a common, agreed upon style, for your team – common format for code reviews.
- Some components may not be fully integrated into Anypoint Studio, for example, the parallel-foreach component. XML is the only option (at least in Studio 7.4.2 w/Runtime 4.2).
Cons:
- Choosing from the full library of connectors, scopes and components is not self-evident and requires some experience in knowing what is needed within a flow.
Using Both Efficiently
Start with the graphical view then move to XML.
Graphical
For the sake of this discussion, I am lumping the Global Elements view in with the graphical space. It’s often easiest to use the graphical perspective when wiring nested configurations, for example, configuring the use of Object Store. When configuring an action, there are config references and Object Store references. Laying it out with the graphically simplifies creating the interdependencies.
e.g.
<os:retrieve-all-keys doc_name="Retrieve all Ids" objectStore="objectstore"/>
<os:config name=“objectstore-config" doc_name="ObjectStore Config">
<os:connection >
<reconnection >
<reconnect count="3" frequency="3000"/>
</reconnection>
</os:connection>
</os:config>
<os:object-store name=“objectstore"
doc_name="Object store"
config-ref="objectstore-config"
entryTtl="30"
entryTtlUnit="DAYS"
expirationIntervalUnit="DAYS"/>
Once defined graphically, I move directly to XML to clean up the file (more on this later).
- Start flow scaffolding visually – optional
- Set breakpoints for debugging
- Generate MUnit scaffolding and creation
XML
This is where most of my time is spent.
- Full flow development
- Choose meaningful names for flows, scopes, components, etc. (not exclusive to XML perspective).
- Adhere to the single responsibility principle:
- Sub and private flows for isolated processing.
- Facilitates testing.
- Set all attributes (except doc:id).
- Any default values for a component are not set in graphical view, explicitly set all configuration attributes for clarity.
- doc:id is clutter, it is automatically added by Studio when composing flows graphically (harkens back to IBM’s VisualAge IDE).
- Its primary use is for metadata in components and when doing graphical DataWeave mapping.
- Recommend using the online DataWeave Editor for DataWeave script development/testing.
- MUnits should avoid using the doc:id as it obfuscates your unit tests.
- If the doc:id gets regenerated or deleted, tests break.
- Use another explicit attribute for contextual clarity in your MUnit markup. (see example)
- Note: this approach is not without its renaming concerns. As a best practice, when renaming attributes, always execute your maven tests to verify your changes had no impact.
- Use a single string, uniquely identifiable naming convention such as snake_case or kebab-case for search-ability.
- e.g.
- Reformat code using preferences settings. These are a team’s personal preference and should be shared for uniformity of code.
- e.g.
<munit-tools:mock-when doc_name="Mock when login-flow" processor="flow-ref">
<munit-tools:with-attributes >
<munit-tools:with-attribute whereValue="login-flow" attributeName="name" />
</munit-tools:with-attributes>
<munit-tools:then-return >
<munit-tools:variables >
<munit-tools:variable key="sessionId" value="#['1234']" mediaType="application/java" encoding="UTF-8" />
</munit-tools:variables>
</munit-tools:then-return>
</munit-tools:mock-when>
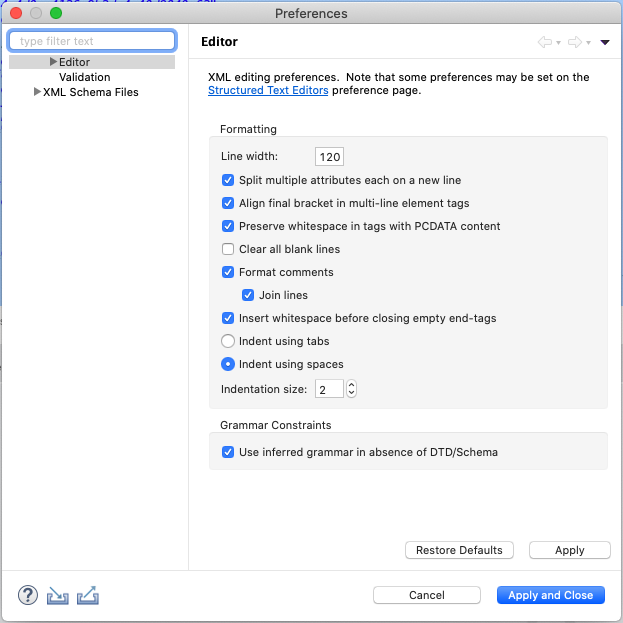
- While not the ideal format, it is a starting point. When making formatting part of your process, adding components and formatting as you go results clean and easy to follow markup. This results in a common look and feel for any KT, code reviews, and facilitates developer adoption when maintenance of an application is transferred to another.
Summary
The primary benefit of working in XML is it provides a more complete view of the configuration of your flows with less de-referencing (property de-referencing aside). Working this way also eliminates the cerebral context switch and facilitates a cleaner, organized view of message processing.
Visual clutter is still clutter. Understanding one’s own mind and adopting behaviors, approaches, or paradigms that play to one’s efficiencies is the intent of this approach. The more we can do to cleanly organize and structure code and/or markup, the more productive we will be.
Finding the right balance is a personal endeavor, however establishing an XML format early, documenting it for your project, as well as communicating to new developers, should be part of every projects’ effort. I’ve personally found that adoption of working in XML by teammates is well received for the points identified in the post.
Regardless of whether you and your teammates work exclusively in the graphical view or some ratio of both, having a standard format gives your code a uniform look and is ultimately an indicator of organized development.
Lastly, it’s completely understood that this content is an opinion piece. Feel free to take what you think works and toss out what doesn’t. I appreciate your time spent reading this.