
MuleSoft’s expression language, DataWeave, is a powerful module a part of the MuleSoft platform. This tool can be very helpful, especially when working with delimited files. From my own experience, I have come across a few tips and tricks when using MuleSoft DataWeave for delimited files that I believe you will find helpful as well!
Using Invisible ASCII Characters as Delimiters in DataWeave
There will be use cases where you have to transform the incoming payload and output a delimited file. In most of the cases, it would be a CSV file where you have a comma (“,”) as the delimiter which can be achieved by defining the output format as application/csv in DataWeave.
{{cta(‘0946bba7-a9e1-4c31-a2c3-b9c5b82e85db’,’justifycenter’)}}
If you are to use a custom character as the delimiter in your output file, you can do so by using the separator parameter at the output. MuleSoft has provided a list of parameters you can use for CSV reader and writer properties that can be found here.
For the purpose of this blog, we will only be focusing on two of the properties that are available. The first one that was mentioned above is the separator parameter, which separates records from another, and the header parameter, that indicates whether the first line of the output contains header names.
As mentioned above this blog deals with how to use invisible ASCII characters like unit separator (US), record separator(RS), etc .., as your delimiter
As shown in the example below, you pass the separator property and the values to be passed for this property should be in the Unicode Escape Sequence format. If you take a look at the snippet, the separator value is u001E where u is the Escape Sequence Representation and 001E” is the Hexadecimal Representation of the record separator (RS) ASCII character
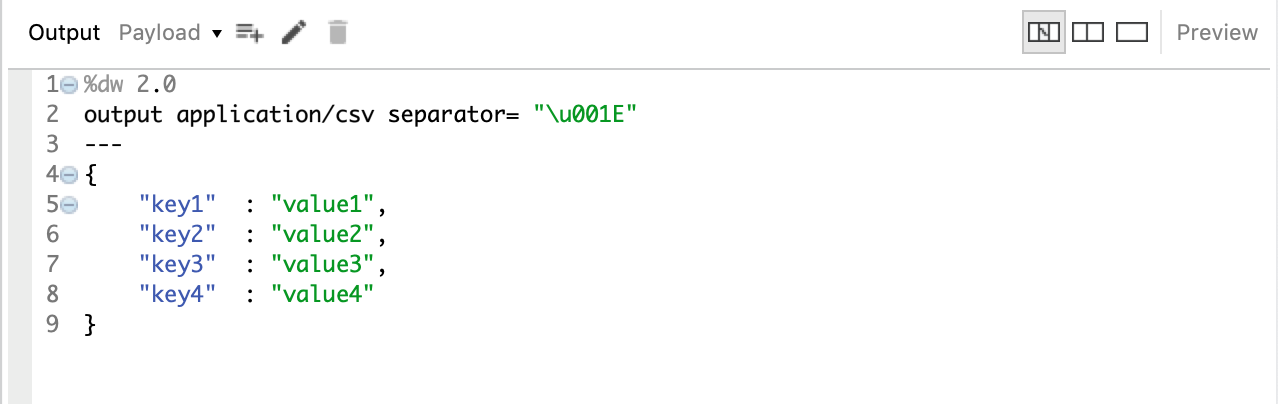
The output of the above snippet, when opened as a text file, a single string with no delimiters will be shown as it is below:
![]()
But if you actually open this file in a text editor like Notepad++ or Sublime Text it will look like this:

Similarly, you can use any invisible ASCII character by passing the Unicode Escape Sequence as the value of separator. If you want to remove the header from your output you can always pass another property at the output that says header=false which will omit the header in your output like this:
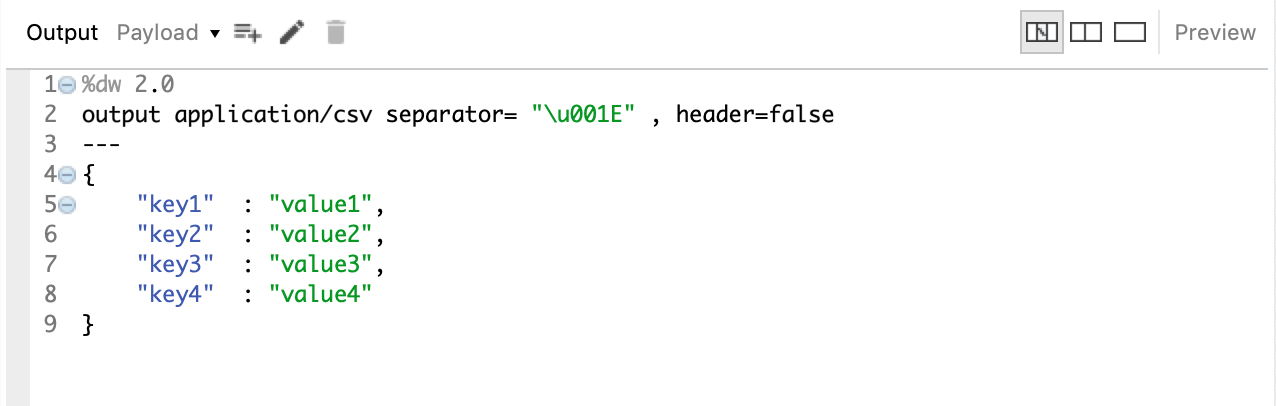
This would output a delimited file with record separator as the delimiter and the header will be omitted meaning the data is populated from line 1 as shown here:
![]()
Comparing Two Delimited Files Using DataWeave
This next tip will come in handy when comparing two delimited files using DataWeave. The use case is when there are two delimited files and certain matching keys in both the files, we then want to extract a certain value from the first file and map it to the second file.
Here I have two pipe(“|”) delimited files, the first file has 4 fields Account, FirstName, LastName and AccountId while the second file has the fields Account, FirstName, LastName, and DOB.
This use case will be generating a JSON output out of the data in these two files. If the Account, FirstName, and LastName fields in the second file match the values in the first file, then we need to extract the AccountId field from the second file.
We will be creating a map with the data in the first file where the key will be Account, FirstName, and LastName, and the value will be AccountId. Then, we loop through the second file where we form a string by appending Account, FirstName, and LastName and we will lookup this key in the map we formed out of the first file.

In the snippet above, the first step is creating an empty variable named dataInFirstFile with java as the output would create an empty LinkedHashMap.
The next step is reading the data from the file and saving the data in the file to the variable file1data.
Once we have the file data in the file1data variable we go to DataWeave and we split the data in the file by new line character (“n”) which will make it an array of string with each element being each line of the file. Then we split each element in the array with the delimiter and remove the first line of the file (Headers) using the splitAt function from array in DataWeave 2.2.0. We are then able to loop through the array of records and split each line by the delimiter,, in this case, it’s “|” so that would output an array of arrays which would look like this:

So I am looping through this array using “map” and “$” in this case would be each array so I pick the values by their index and form a map of key-value pairs and as we loop through each iteration we add the values to the dataInFirstFile variable and the output is also stored in dataInFirstFile variable.
Next step is reading the data from the second file and we will follow the same approach, rip off the header and split data into array of arrays as above and we will make a key with the Account, FirstName, LastName fields in the second file and lookup this key in the map generated out of the first file which is stored in the dataInFirstFile variable. The below snippet displays how this is done:

This will output a JSON with AccountId field computed from the first file as shown below:

Now you know how to use ASCII characters as delimiters and how to compare two delimited files all while using MuleSoft DataWeave. These are just a couple of tricks that I use when working with DataWeave, let me know what some of your favorites are in the comments below!
{{cta(‘6f6e43a6-2473-4764-b134-9773fc2cbe8c’,’justifycenter’)}}
