
This blog post is for anyone using MuleSoft who may be experiencing issues tracking API calls through their application network. If you have the Titanium support package, you can use the Log Search in Anypoint Monitoring to filter by a correlation ID across all the applications to find the root cause. If you don’t have the Titanium package, you’ll have to search each application’s logs separately for the transaction. If you’ve had to do this in the past, you know how difficult and time consuming it can be. What if you could put the logs for each of the applications in one place so they can be analyzed together?
Elastic Cloud makes analyzing logs faster. In the blog, I’ll walk you through the setup of an Elastic Cloud trial account which can be helpful in improving the observability of your applications. 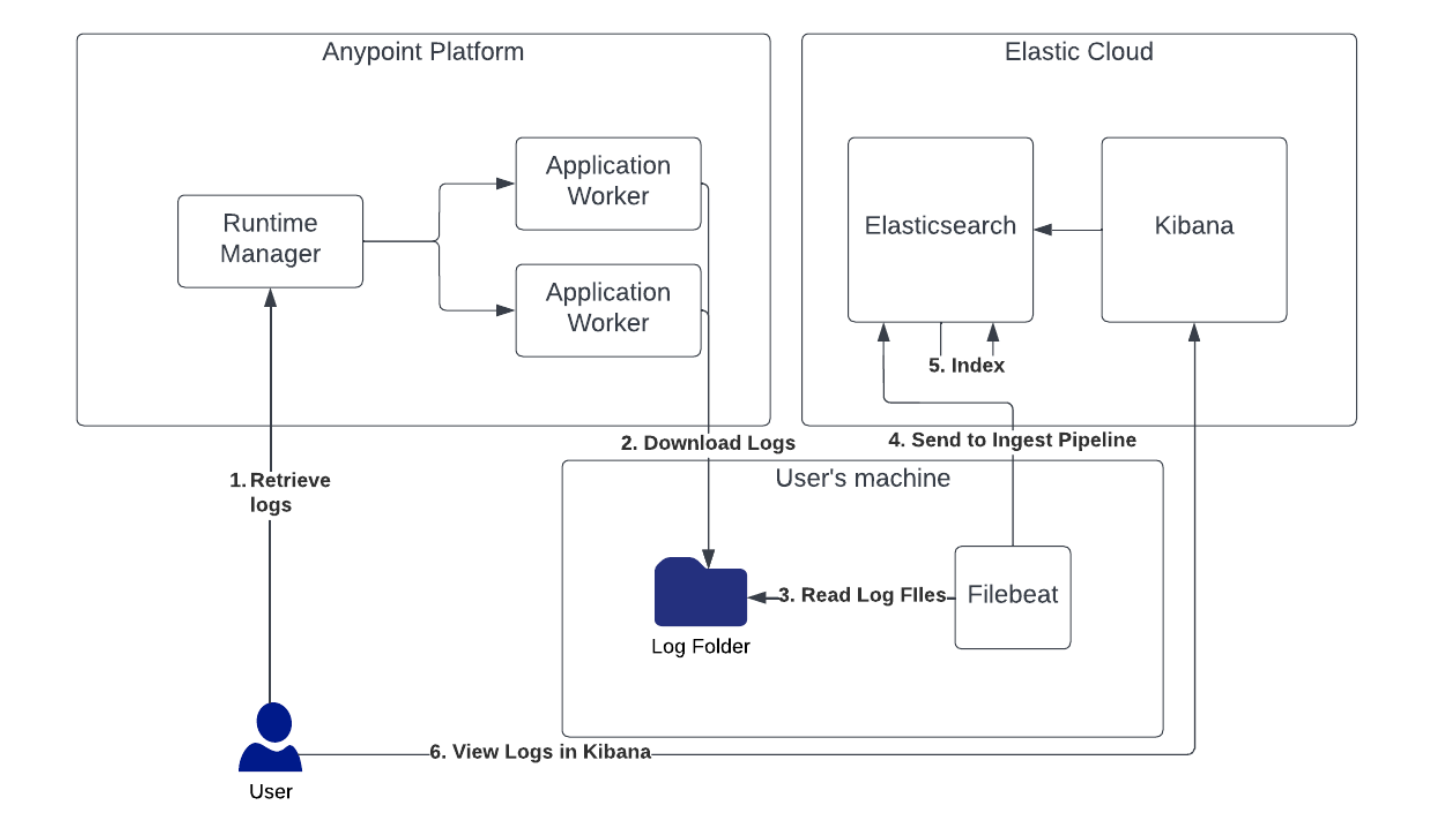
If your organization is using Splunk, see our blog post about using the Splunk Universal Forwarder.
Starting An Elastic Cloud Trial
Starting a trial account in Elastic Cloud is easy — no credit card required. Go to https://www.elastic.co/ and click on the Try Free button on the top right, enter your email address and password, and then click on Start free trial.
At this point, you will need to select which cloud provider to use for your Elastic cluster deployment. Since CloudHub runs in AWS, I recommend choosing AWS and using the same region as your CloudHub VPC. This is just in case you decide to keep the Elastic cluster past your free trial period and ship logs directly from your MuleSoft applications. I also recommend choosing the Storage optimized (dense) hardware profile since you’ll be storing a potentially large number of log messages.

After clicking on Create deployment, you will be given the root credentials for your Elastic cluster. Save these credentials and keep them safe. I recommend using LastPass, 1Password, or Bitwarden. The credentials will be used in a future step to send your logs into your cluster.
After about 5 minutes, your cluster will be ready. Clicking on Continue will bring you to the welcome page. Click on Explore on my own to continue to the Kibana home page. Kibana is the web application you use to interact with your Elastic cluster.
Configuring Elastic Cloud for CloudHub Log Ingestion
Now that your Elastic cluster is set up, you need to configure an ingest pipeline so it is ready to accept the logs from your MuleSoft applications in CloudHub. The ingest pipeline will parse each log message it receives, extracting the timestamp, log level, logger, thread name, event ID, and message fields. These fields will be stored separately so they can be searched reliably and efficiently.
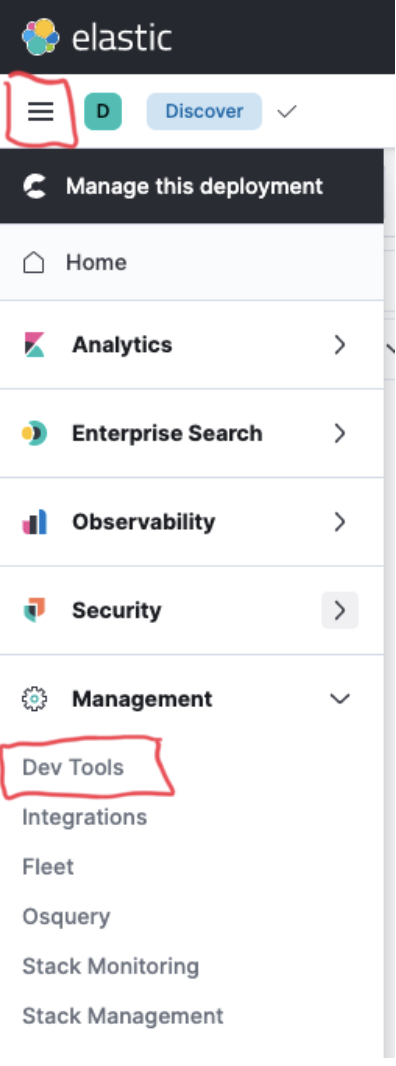
From the Kibana home page, click on the menu button on the top left corner of the page – it looks like three horizontal lines. Then click on Dev Tools to bring up the Console UI. This UI allows you to send HTTP requests to the Elasticsearch API that is used by Kibana.
Copy the request below, paste it into the Console UI, and click on the green play button to execute it. This will create an ingest pipeline called cloudhub-logs, which can parse the CloudHub logs.
PUT _ingest/pipeline/cloudhub-logs
{
"processors": [
{
"grok": {
"field": "message",
"patterns": [
"\[%{TIMESTAMP_ISO8601:timestamp}\] %{LOGLEVEL:log.level}%{SPACE}%{NOTSPACE:log.logger} \[%{GREEDYDATA:thread}\]: (event:%{NOTSPACE:mulesoft.event}%{SPACE})?%{GREEDYMULTILINE:message}"
],
"pattern_definitions": {
"GREEDYMULTILINE": "(.|n)*"
}
}
},
{
"remove": {
"field": "@timestamp"
}
},
{
"date": {
"field": "timestamp",
"formats": [
"yyyy-MM-dd HH:mm:ss.SSS"
],
"target_field": "@timestamp"
}
},
{
"remove": {
"field": "timestamp"
}
}
]
}After executing the above, you will see the below response on the right side of the screen.

Ingesting Logs with Filebeat
We need to use a tool called Filebeat to read the log files and send each message to Elastic. We will be using the Filebeat container to make setup simpler.
The first step is to run the Filebeat setup command to load resources needed for Filebeat into Elastic. In order to connect it to the correct Elastic cloud instance, we need the credentials you saved while setting it up and the Cloud ID for your deployment.
The Cloud ID can be found by clicking on the Manage this deployment link from the menu in Kibana. This link brings you to the infrastructure management portion of Elastic Cloud. In the middle, on the right side of the page, you will find the Cloud ID for your deployment (surrounded by a red box in the screenshot below). There is a button at the end of it to copy the value to the clipboard.

With that information, run the below command to execute the setup. Be sure to separate your root username and root password with a colon (:).
docker run
docker.elastic.co/beats/filebeat:8.3.0 setup
-E cloud.id=${YOUR_CLOUD_ID}
-E cloud.auth=${YOUR_ROOT_USER_NAME}:${YOUR_ROOT_USER_PASSWORD}After the setup is complete, you need to create the Filebeat configuration file. Save the text below to a file named filebeat.docker.yml. I will refer to this file as ${YOUR_FILEBEAT_DOCKER_YML_FILE} in a future step.
filebeat:
inputs:
- type: filestream
id: my-stream
pipeline: cloudhub-logs
index: logs-cloudhub-%{+yyyy.MM.dd}
paths:
- /var/log/*.log
parsers:
- multiline:
type: pattern
pattern: '^['
negate: true
match: afterThis configuration tells Filebeat to read all *.log files from /var/log and send them to the logs-cloudhub-${+yyyy.MM.dd} index in Elastic after processing them through the cloudhub-logs ingest pipeline. It is also configured to allow multiline log messages, such as stack traces.
Now, we need to create a directory on your filesystem to map to the /var/log directory in the container. When you drop a log file into the directory, Filebeat will process it into Elastic. I will refer to this directory as ${YOUR_LOG_DIRECTORY} in the next step.
After creating the directory, run the following command to start the FIlebeat container. Be sure to separate your root username and root password with a colon (:).
docker run -d --name=filebeat --user=root
--volume="${YOUR_FILEBEAT_DOCKER_YML_FILE}:/usr/share/filebeat/filebeat.yml:ro"
--volume="${YOUR_LOG_DIRECTORY}:/var/log"
docker.elastic.co/beats/filebeat:8.3.0 filebeat
-e --strict.perms=false
-E cloud.id=${YOUR_CLOUD_ID}
-E cloud.auth=${YOUR_ROOT_USER_NAME}:${YOUR_ROOT_USER_PASSWORD}Now that Filebeat is running, go to your application in Runtime Manager and download the log files from the applications you are having trouble with. In Runtime Manager, click on the application name, then click on Logs to show the log messages.
On the right side of the logs page, click on the download button next to the worker from which you would like to download the logs. Next, select Logs to get all of the log messages from the chosen worker.

After you’ve downloaded the log files, put them in ${YOUR_LOG_DIRECTORY} so they can be processed. Depending on how large your log files are, it may take several minutes for all of the logs to be ingested into Elastic.
Searching in Elastic
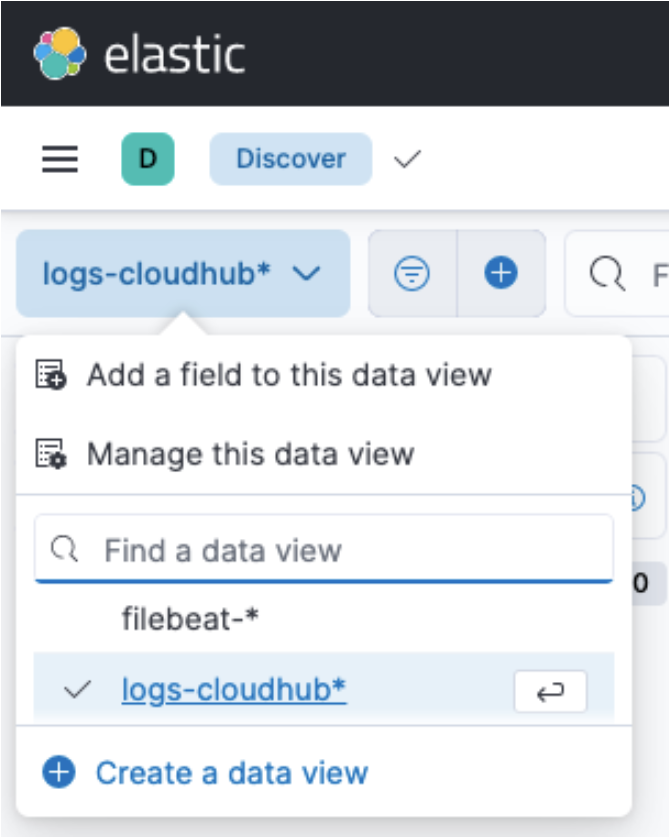
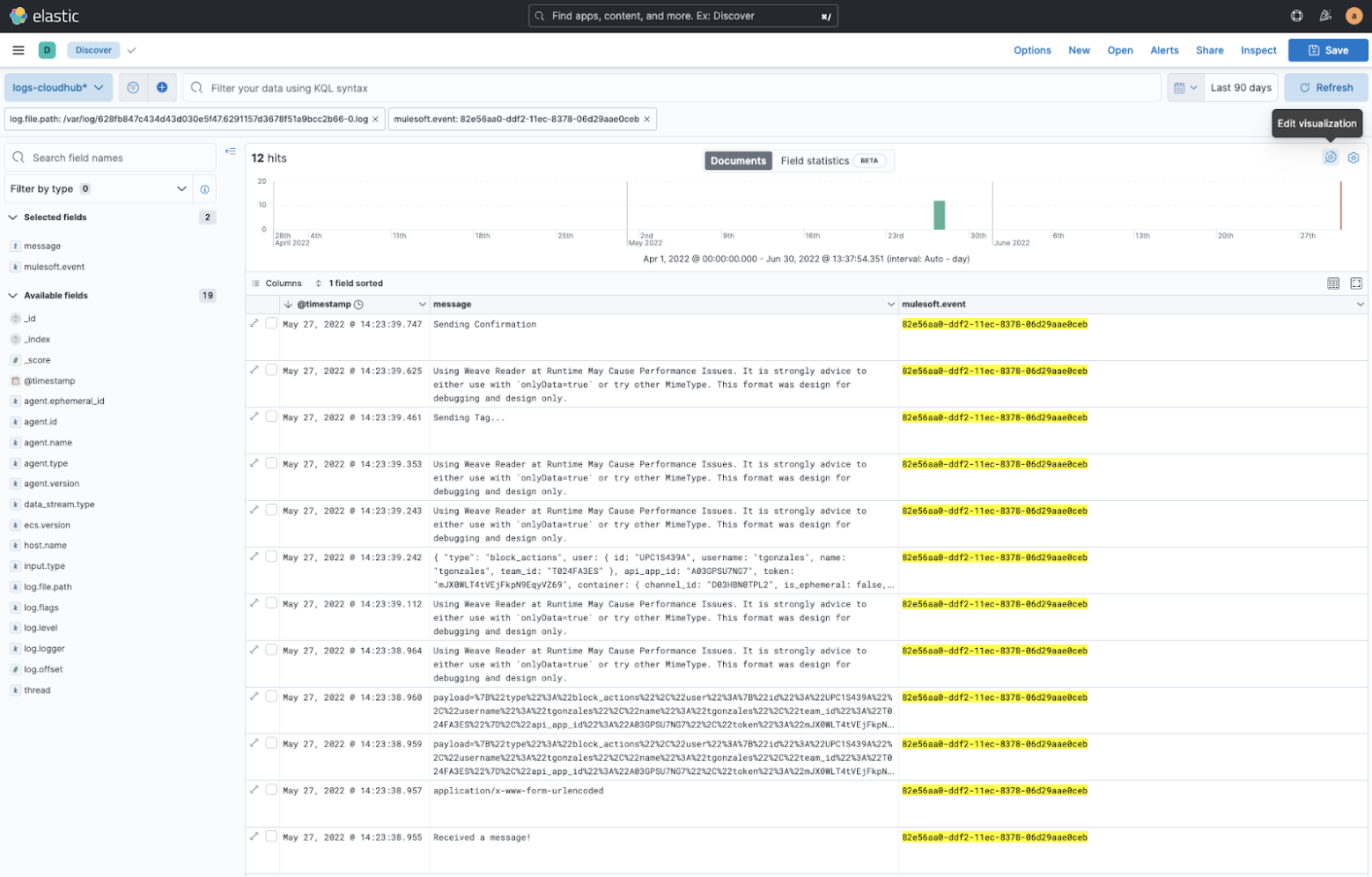
Now that your logs are ingested into Elastic, you will need to back into Kibana so you can analyze them. From the Kibana home page, open the menu, then click on Discover under the Analytics section. This will open a page where you can view the logs. You will have to click on the Create a data view button under the blue button in the top left corner. Create a data view called logs-cloudhub-*. This will allow you to view all of the logs that you have ingested.
You will also need to change the time frame you are looking at so you include the time for the logs you ingested. You can use relative time, or specify an exact time frame.

Once you’re in the correct time frame, you can add filters and display columns to find what you’re looking for. See this page for they query language syntax: https://www.elastic.co/guide/en/kibana/current/kuery-query.html
Diving Deeper into Observability
This is a sample of the functions you can do with Elastic, manually. It becomes very powerful when you automate the ingestion of logs directly from your MuleSoft applications and start adding other observability capabilities.
AVIO Consulting offers an observability package for MuleSoft. This package makes it easy to evaluate and take action on your logs, key metrics, and health stats If this interests you, please contact us to schedule a personalized demo.